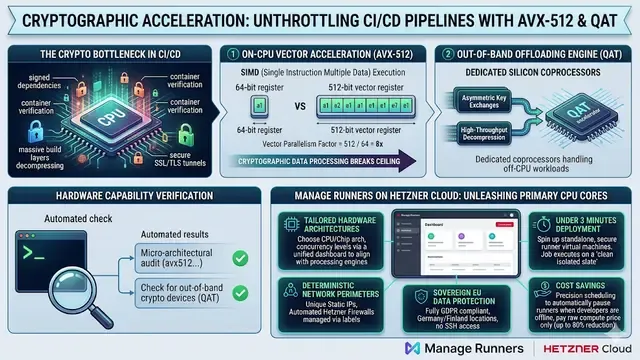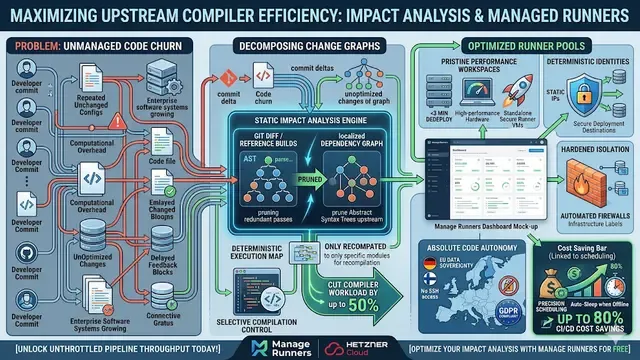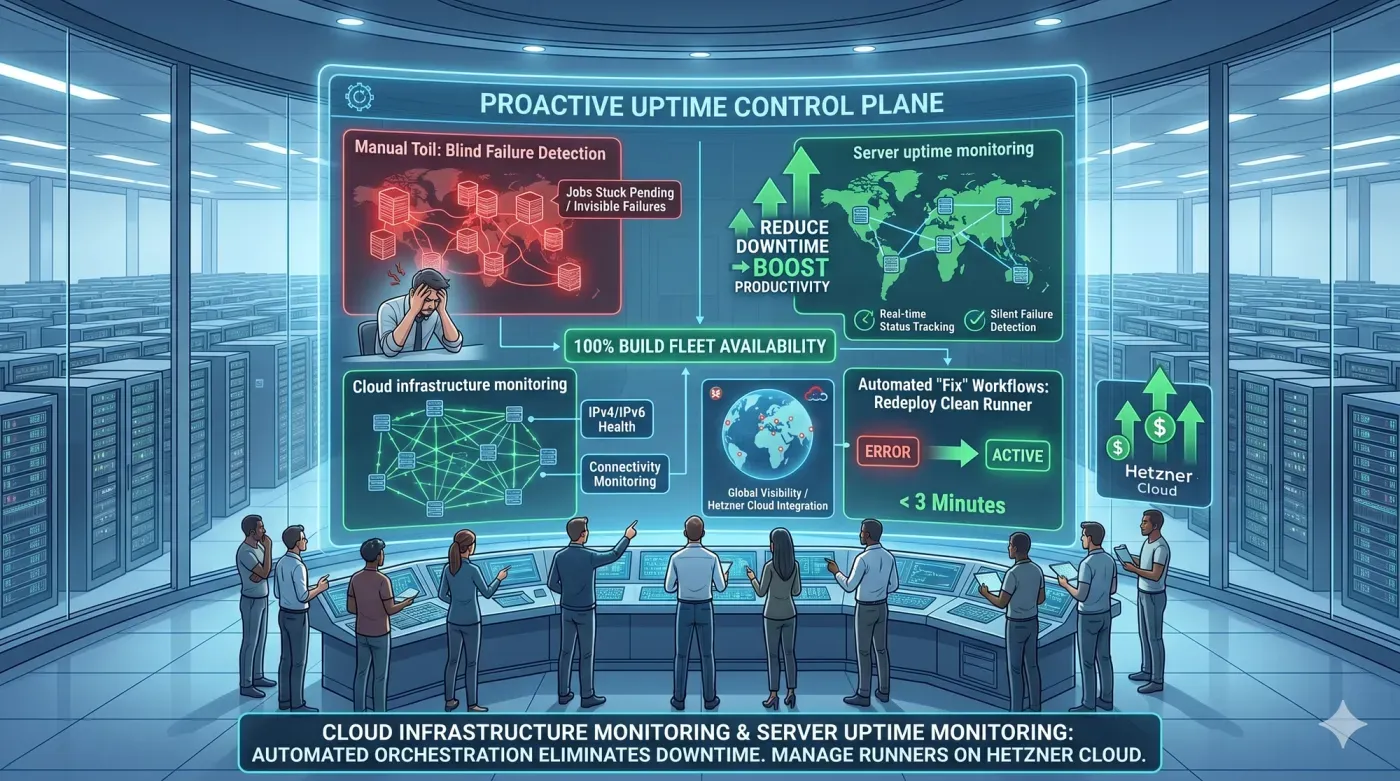
In the high-stakes engineering environment of 2026, visibility is the foundation of reliability. For DevOps teams, cloud infrastructure has evolved from a simple "ping" test into a comprehensive strategy for preventing pipeline stalls. By maintaining rigorous server uptime monitoring, organizations can detect "silent failures" such as hung runners or expired tokens before they impact build velocity. The goal is simple: ensure that your build fleet is always ready, always secure, and consistently cost-optimized.
1. The Problem: The Invisibility of Runner Failure
The primary cause of CI/CD downtime isn't usually a major cloud outage; it's the small, undetected failure of individual runners. Without a robust approach to cloud infrastructure , a runner can enter an "Error" or "Zombied" state without alerting the team. This leads to job queues that grow indefinitely, "Pending" states that never resolve, and developers wasting hours waiting for builds that will never start.
2. The Agitation: The Cost of Reactive Troubleshooting
When server uptime monitoring is treated as an afterthought, the team is forced into a reactive cycle. You only realize a runner is down when a deployment fails or a release deadline is missed. This "manual toil" involves:
- SSH-ing into various VMs to check service statuses.
- Checking firewall logs for blocked connectivity.
- Manually re-registering GitLab tokens that have desynchronized. This approach isn't just inefficient it's expensive. Every hour of downtime is an hour of "lost" developer productivity, which often outweighs the cost of the infrastructure itself.
3. The Solution: Proactive Visibility and Automated Recovery
Transitioning to a high-availability model requires moving from manual checks to an automated orchestration layer. Effective cloud infrastructure monitoring should provide a real-time status of every node in your fleet.
- Real-time Status Tracking: Moving beyond logs to a live dashboard that reflects states like
Active,Creating, orError. - Connectivity Monitoring: Instantly viewing IPv4/IPv6 health to ensure runners can communicate with the GitLab control plane.
- Guided Recovery: Implementing "Fix" workflows that can redeploy a clean, hardened runner from a verified template in minutes.
# Example: Simple health check for a CI/CD runner service
# Integrated monitoring ensures this state is reported to your dashboard instantly.
systemctl is-active gitlab-runner || (echo "CRITICAL: Runner service is down" && exit 1)4. Manage Runners: Effortless Uptime for DevOps Teams
Manage Runners simplifies the complexities of cloud infrastructure monitoring by providing a centralized dashboard for your build fleet on Hetzner Cloud. Instead of managing individual servers, you manage a high-performance engine of delivery.
The platform provides the essential tools to sustain server uptime monitoring with zero manual overhead:
- Status Monitoring: Real-time visibility into the lifecycle of every runner (Creating, Configuring, Active, or Error).
- Integrated Error Reporting: Catch common issues like GitLab token validation failures instantly through the dashboard.
- Automated "Fix" Workflows: Don't waste time troubleshooting. Use guided workflows to redeploy a clean runner in less than 3 minutes.
- Hetzner Specifics: Deep integration with Hetzner Cloud ensures you see geographic data and connectivity status at a glance.
5. Conclusion
Reliable infrastructure isn't built on hope; it’s built on visibility. By prioritizing Cloud infrastructure monitoring, you eliminate the bottlenecks that slow down your team and drain your budget.
Ready to stop the maintenance toil and secure 100% uptime? [Start your Server Uptime Monitoring journey with Manage Runners today] and scale your CI/CD pipelines on Hetzner with total confidence.